Jina
- 0 ratings
Cloud-native neural search framework for any kind of data.
Self-host this app for $0.99/mo only!

![]()
Build multimodal AI services with cloud native technologies



![]()
Build and deploy a gRPC microservice • Build and deploy a pipeline
Applications built with Jina enjoy the following features out of the box: 🌌 **Universal** - Build applications that deliver fresh insights from multiple data types such as text, image, audio, video, 3D mesh, PDF with [LF's DocArray](https://github.com/docarray/docarray). - Support for all mainstream deep learning frameworks. - Polyglot gateway that supports gRPC, Websockets, HTTP, GraphQL protocols with TLS. ⚡ **Performance** - Intuitive design pattern for high-performance microservices. - Easy scaling: set replicas, sharding in one line. - Duplex streaming between client and server. - Async and non-blocking data processing over dynamic flows. ☁️ **Cloud native** - Seamless Docker container integration: sharing, exploring, sandboxing, versioning and dependency control via [Executor Hub](https://cloud.jina.ai). - Full observability via OpenTelemetry, Prometheus and Grafana. - Fast deployment to Kubernetes and Docker Compose. 🍱 **Ecosystem** - Improved engineering efficiency thanks to the Jina AI ecosystem, so you can focus on innovating with the data applications you build. - Free CPU/GPU hosting via [Jina AI Cloud](https://cloud.jina.ai). Jina's value proposition may seem quite similar to that of FastAPI. However, there are several fundamental differences: **Data structure and communication protocols** - FastAPI communication relies on Pydantic and Jina relies on [DocArray](https://github.com/docarray/docarray) allowing Jina to support multiple protocols to expose its services. **Advanced orchestration and scaling capabilities** - Jina lets you deploy applications formed from multiple microservices that can be containerized and scaled independently. - Jina allows you to easily containerize and orchestrate your services, providing concurrency and scalability. **Journey to the cloud** - Jina provides a smooth transition from local development (using [DocArray](https://github.com/docarray/docarray)) to local serving using (Jina's orchestration layer) to having production-ready services by using Kubernetes capacity to orchestrate the lifetime of containers. - By using [Jina AI Cloud](https://cloud.jina.ai) you have access to scalable and serverless deployments of your applications in one command.

pip install jina transformers sentencepiece
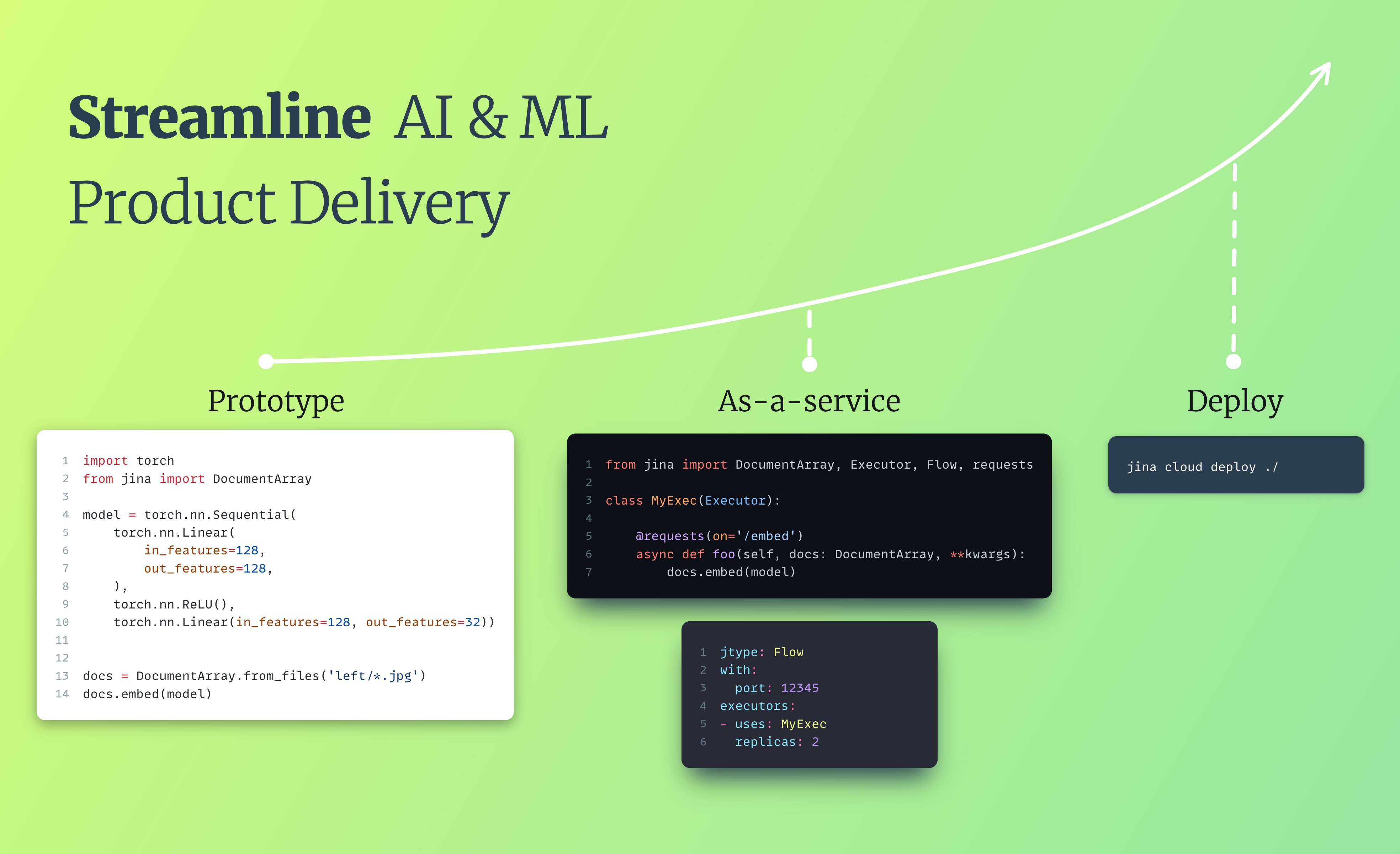
translate_executor.py |
|---|
|
Python API: deployment.py |
YAML: deployment.yml |
|---|---|
|
|
──────────────────────────────────────── 🎉 Deployment is ready to serve! ─────────────────────────────────────────
╭────────────── 🔗 Endpoint ───────────────╮
│ ⛓ Protocol GRPC │
│ 🏠 Local 0.0.0.0:12345 │
│ 🔒 Private 172.28.0.12:12345 │
│ 🌍 Public 35.230.97.208:12345 │
╰──────────────────────────────────────────╯from docarray import Document
from jina import Client
french_text = Document(
text='un astronaut est en train de faire une promenade dans un parc'
)
client = Client(port=12345) # use port from output above
response = client.post(on='/', inputs=[french_text])
print(response[0].text)an astronaut is walking in a park Python API: flow.py |
YAML: flow.yml |
|---|---|
|
|
─────────────────────────────────────────── 🎉 Flow is ready to serve! ────────────────────────────────────────────
╭────────────── 🔗 Endpoint ───────────────╮
│ ⛓ Protocol GRPC │
│ 🏠 Local 0.0.0.0:12345 │
│ 🔒 Private 172.28.0.12:12345 │
│ 🌍 Public 35.240.201.66:12345 │
╰──────────────────────────────────────────╯from jina import Client, Document
client = Client(port=12345) # use port from output above
french_text = Document(
text='un astronaut est en train de faire une promenade dans un parc'
)
response = client.post(on='/', inputs=[french_text])
response[0].display()wget https://raw.githubusercontent.com/jina-ai/jina/master/.github/getting-started/jcloud-flow.yml
jina cloud deploy jcloud-flow.yml


| Normal Deployment | Scaled Deployment |
|---|---|
|
|
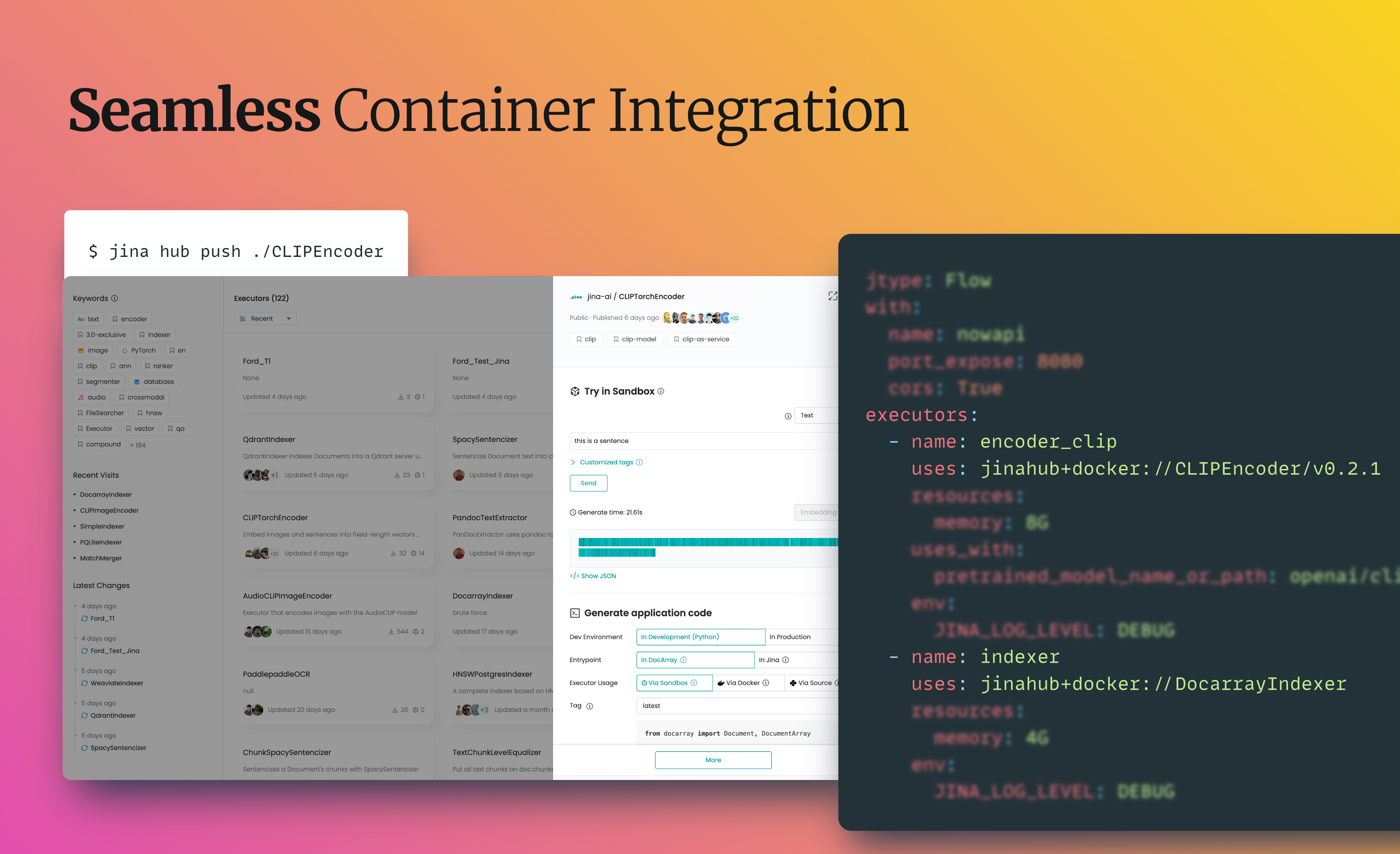
jina hub new jina hub push .

jina export kubernetes flow.yml ./my-k8s
kubectl apply -R -f my-k8sjina export docker-compose flow.yml docker-compose.yml
docker-compose upfrom docarray import DocumentArray
from jina import Executor, requests
class Encoder(Executor):
@requests
def encode(self, docs: DocumentArray, **kwargs):
with self.tracer.start_as_current_span(
'encode', context=tracing_context
) as span:
with self.monitor(
'preprocessing_seconds', 'Time preprocessing the requests'
):
docs.tensors = preprocessing(docs)
with self.monitor(
'model_inference_seconds', 'Time doing inference the requests'
):
docs.embedding = model_inference(docs.tensors)


Please login to review this project.
No reviews for this project yet.


A lightweight alternative to elasticsearch that requires mi…
Blazing fast, typo-tolerant open source search engine optim…
A self-hosted, ad-free, privacy-respecting metasearch engin…
Comments (0)
Please login to join the discussion on this project.